破局数据中心多节点扩展挑战!NVIDIA提出三类参考架构
2020-01-13 智东西 编辑:单瑜
人工智能(AI)和深度学习正成为越来越多企业的核心竞争力。随着智能化应用的高速普及,很多传统数据中心都面临着众多难题。单个 GPU 或服务器难以做到快速访问大量计算资源,但要跨多个节点扩展应用程序,又面临存储、网络等不同系统组件带来的挑战。
对此,NVIDIA 打造了超强深度学习训练性能的 DGX-1 AI 超级计算机,融合多种有助于多节点扩展的系统技术,并基于实践经验,总结出构建多节点系统的建议和多种参考架构设计方案,可协助 IT 管理员以更高的成本效益构建高性能多节点系统。
本期的智能内参,我们推荐《基于 NVIDIA DGX-1 构建多节点环境的注意事项》白皮书,不仅解析提高多节点可扩展性面临的瓶颈,还针对不同的节点数量需求,提出三种在多节点环境中高效配置 DGX-1 架构的解决方案。如需查阅此白皮书《基于NVIDIA DGX-1构建多节点环境的注意事项》,可直接点击“白皮书”进行下载。还可点击“试用”申请测试 NVIDIA DGX-1 AI 超级计算机。
以下为智能内参整理呈现的干货:
要实现良好可扩展性,需确保应用程序在多节点上协调运行多个进程,而任何系统组件存在的瓶颈问题都会影响其有效扩展的能力,这给传统数据中心带来重重困难。
比如在通信方面,如果向节点添加更多 GPU,应用程序线程间的通信成本会导致训练性能明显下降。在标准服务器中,GPU 间的通信受 PCIe 总线限制,不同服务器上的 GPU 通信又受典型数据中心网络以太网的影响。对通信模式作出不明确假定也会导致相同和不同系统上的 GPU 间出现不必要的流量。
海量数据处理和管理对读取缓存也提出了新的需求,要求有巨大读取带宽通路,同时能在训练期间多次重复访问相同数据。
软件也是制约系统可扩展性的一个关键要素。并非所有深度学习框架都能保持一致的高效扩展,因此必须选择适当的框架和版本,以及合适的作业调度软件,以确保其可扩展性远高于支持硬件。
除了上述因素外,本白皮书也分析了关于整体集群、机架设计空间、数据中心功率密度等其他方面的考量。基于 NVIDIA 与客户长期的交流,NVIDIA 也探讨了一些应对这些挑战的成熟解决方案。
NVIDIA 提供的参考方案基于 NVIDIA DGX-1 超级计算机,这是专为深度学习打造的集成系统,旨在最大限度提升深度神经网络的训练速度。有关 NVIDIA DGX-1 的核心技术和性能介绍,可参阅《性能媲美250台CPU服务器,英伟达DGX-1的实力有多彪悍?》
DGX-1 为何能最大限度提高多 GPU 和多节点性能?这源自 DGX-1 采用的多种新技术。
NVIDIA 在 DGX-1 的节点内 GPU 之间,采用超高带宽通路 NVLink,相比基于 PCIe Gen3 的传统互连,速度可提升 10 倍。此外,NVIDIA还为每个系统配备 4 个 InfinBand 100 Gb/秒扩展数据速率(EDR)端口,并搭配软件技术提供 GPU 间的优化通信方法。
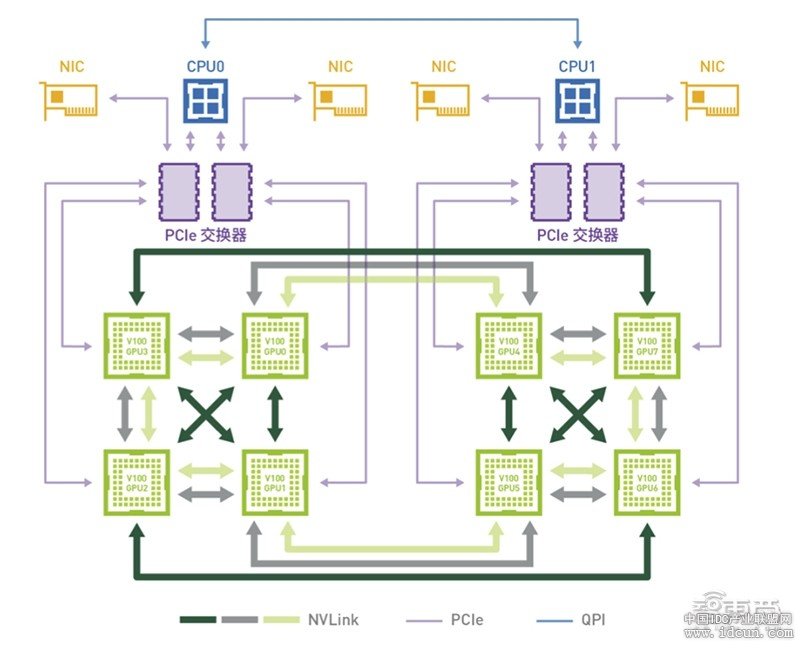
▲DGX-1 采用 8-GPU 的混合立体互联网络拓扑
为了帮助数据中心工作人员进一步节省构建 AI 基础设施所需的时间和试错成本,NVIDIA 通过与领先的存储、网络交换技术提供商合作,提出一种经优化的数据中心机架—— DGX POD 交付节点(Point of Delivery)。
基于此,NVIDIA 将其超大规模数据中心 AI 部署经验转化为可复制方案,将包含多台 DGX-1、存储服务器、网络交换机等设备的最佳实践方案,融入一系列 DGX POD 数据中心交付节点设计参考架构中。
智东西曾在《NVIDIA集成AI超算中心经验,打造AI就绪型数据中心》一文中对《NVIDIA DGX POD 数据中心参考设计》白皮书进行亮点解读,并附以白皮书下载链接。

▲ DGX POD 参考架构正面图
陆续有 NVIDIA 的合作伙伴已经开始基于 DGX POD 推出具体的配置方案。例如, NetApp 推出的 NetApp ONTAP AI 解决方案。
在提供 DGX POD 一站式交付节点解决方案前,NVIDIA 曾打造了由 125 个 DGX-1 节点组成的 AI 超级计算机 SATURNV。
SATURNV 托管了 1000 个 NVIDIA Tesla GPU,计算能力媲美 3 万多台 x86 服务器,一经推出就登上了 Green 500 超算榜第一名,被称为全球最经济高效的超算,同时它也是最快的 AI 超算。
在构建 SATURNV 的过程中,NVIDIA 积累了横向扩展 DGX-1 架构的指导基础,其中采用的一些技术及方案均可供 IT 架构师参考。
比如,为了能更快在跨集群延伸的节点间传递数据,NVIDIA 开发了一种高性能双层 InfiniBand 交换架构,并使用 GPUDirect RDMA 技术,最大限度降低延迟并提高集群节点间的带宽。NVIDIA 也在存储等方面提供了一些兼顾性能和成本效益、且简单可执行的建议。
针对不同环境的性能和算能需求,NVIDIA 提供了三种可能的配置方法,上限服务器节点数量分别为 12、 36、144,以确保在相应节点数量的环境可实现无限制的深度神经网络训练性能。
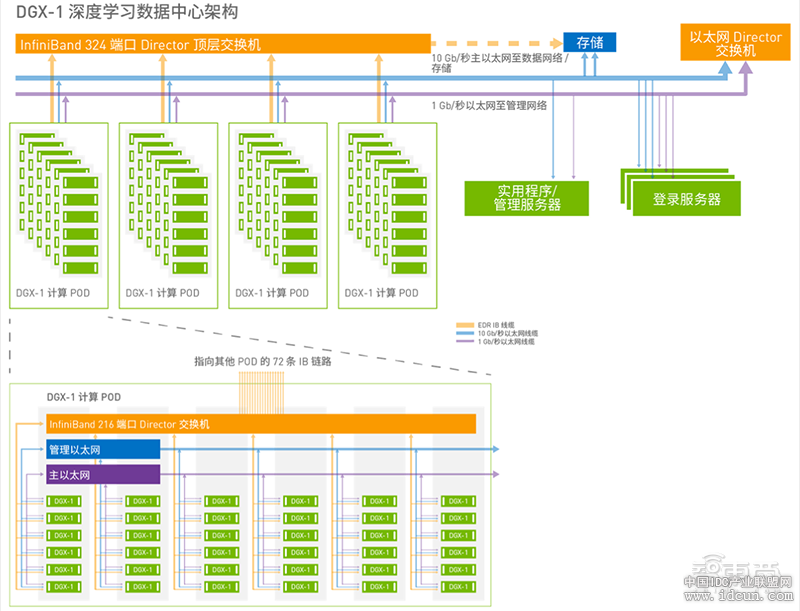
▲NVIDIA DGX-1 深度学习数据中心参考架构(144个服务器)
NVIDIA 充分考虑到每台机架的计算、功率、散热密度等因素,给予的具体建议包括机架、网络、计算、存储、管理等材料的数量和选型。
IT 团队可根据必须考虑的具体目标和成本目标,参考这些配置,然后定制出最符合自身需求的多节点扩展系统。
与此同时,NVIDIA 也与 ISV 合作伙伴紧密协作,提供协助管理 DGX-1 多节点集群的解决方案。这些方案在管理调度 GPU 资源、优化提高吞吐量以及恢复能力方面,可提供非常有效的帮助。
智东西认为,如果能借鉴经过检验的成熟参考架构,IT 架构师、管理员及管理者在面对数据中心的 AI 转型需求时更加游刃有余,帮助团队及组织更快地实现深度学习工作负载的多节点扩展,在大幅提升训练性能的同时,节省部署时间、资本支出及IT管理运营支出等成本。