深度点评亚马逊、微软、谷歌等6大机器学习云行业资讯
微软、Databricks、谷歌、惠普企业和IBM都为解决许多机器学习问题提供了工具。本文将简要分析这6种商业机器学习解决方案的特点。
AWS:替你选择模型
亚马逊试图让机器学习能够为普通人所利用。亚马逊希望的是,分析师只需要理解那些被解决的问题本身,而不需要理解数据科学和机器学习算法。
总的来说,要使用亚马逊机器学习,你首先要把你的数据整理为CSV格式、上传到亚马逊的S3服务;然后你创造、训练和评估你的机器学习模型;最终,你能用它进行批量或实时的预测。每个步骤都是迭代性的,整个过程亦然。机器学习并不是一件简单静态的事,尽管我们可以把算法选择的部分留给亚马逊来做。
亚马逊机器学习支持3类模型——二元分类、多类别分类和回归——每个类型都有一个对应的算法。在优化方面,亚马逊机器学习使用随机梯度下降(SGD),这种方法能在训练数据中建造多序列通路(multiple sequential passes),更新每个小批量样本的特征权重,从而将损失函数最小化。损失函数是指现实值和预测值之间的差异。梯度下降优化法只在连续、可微的损失函数(例如logistic函数和平方损失函数)的情况下工作良好。
对二元分类,亚马逊机器学习使用了logistic回归(logistic 损失函数加上随机梯度下降)。对多类别分类,亚马逊机器学习使用了多元logistic回归(多元 logistic 损失函数加上随机梯度下降)。对回归,亚马逊机器学习使用了线性回归(平方损失函数加上随机梯度下降)。
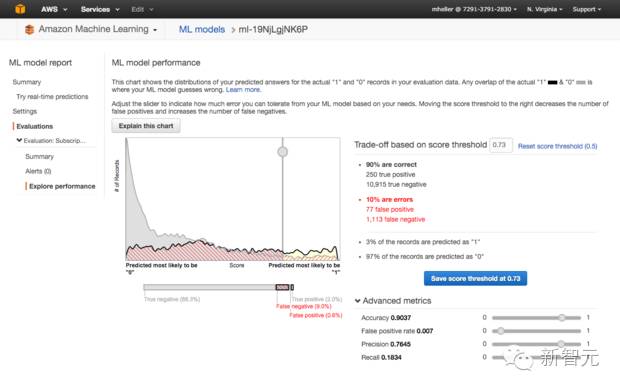
在亚马逊机器学习服务中训练和评估了一个二元分类模型之后,你可以选择你自己的分数阈限,以获得你所想要的误差率。此处,我们把阈限值从默认的 0.5 提高了,这样我们就可以为市场和销售提供更强的指导。
亚马逊机器学习通过目标数据的类型来决定所要解决的机器学习任务的类型。例如,具有数字目标变量的预测问题意味着回归。而对那些具有非数字目标变量的预测问题,如果目标状态是两个,那就对应二元分类模型;如果目标状态是多个,就对应多类别分类模型。
亚马逊机器学习服务中的特征选项保存在清单中。当对数据源的描述性统计被计算好之后,亚马逊就会创造出一个默认的清单。在你将应用于数据的机器学习模型中,你既可使用这个清单,也不用它。一旦你拥有了一个能达到你的评估要求的模型,你就可以用它来建立一个实时网络服务,或批量地产生预测。但请记住,与物理常量不同的是,人的行为随着时间而改变。你需要定期检查你的模型所产生的预测准确度标准,并在需要时重新训练它。
微软Azure:有了经验你再来
与亚马逊不同,微软试图为有经验的数据科学家提供一整套算法和工具。因此,Azure机器学习是更广泛的微软 Cortana 分析套装中的一部分。微软Azure机器学习也拥有拖拽式的界面,以便于构造模型训练和评估来自模块的数据流。
Azure机器学习工具包括导入数据集、训练和发布实验性模型、在Jupyter Notebooks中处理数据和保存已训练的模型等功能。该机器学习工具中包含数十个样本数据集,五个数据格式转换方式,多个读取和写入数据的方式,数十种数据转换和三个用来选择特征的选项。在Azure机器学习服务中,你将为异常检测、分类、聚类和回归找到多种模型;此外还有四种为模型打分的方法、三种评估模型的策略和六种训练模型的过程。你也可以使用两个OpenCV(开源计算机视觉)模块、统计学方程和文本分析工具。
上面这些已包含很多东西了,如果你理解你的生意、数据和模型,那么理论上它们足够用来以任何模型来处理任何数据了。当既有的Azure机器学习工具模块无法实现你想要的东西时,你也可以自己开发Python或R模块。
你可以用Jupyter Notebooks来开发和测试Python 2和Python 3语言模块。Jupyter Notebooks已扩展了Azure机器学习服务的Python客户库,也扩展了scikit-learn、matplotlib和NUmpy,从而能够处理你在Azure中存储的那些数据。Azure Jupyter Notebooks将来也会支持R语言,目前,你可以在本地使用Rstudio以改变Azure的输入输出,或者在微软数据科学VM中安装Rstudio。
当你在Azure机器学习服务中创造一个新实验时,你既可以从零开始,也可以从微软的70个样本开始,这些样本覆盖了大部分常用模型。此外在Cortana Gallery还可以找到其他Azure社区的内容。

微软Azure机器学习服务能迅速产生网络服务以发布训练好的模型。图中这个简单模型来自一篇对Azure机器学习的互动式导论。
要使用Cortana分析过程(CAP),应从计划和安装的步骤开始。这很重要,除非你已经是一名对商业问题、数据和Azure机器学习都十分熟悉的受过训练的数据科学家,并已为项目创造了必要的CAP环境。CAP环境中可以包含一个Azure存储帐号,一个微软数据科学VM,一个HDInsight(Hadoop)群组和一个使用Azure机器学习服务的机器学习工作空间。如果这些选项令你困惑,你可以参考微软的文档。安装好之后,CAP包含5个后续步骤:消化数据、探索性数据分析和预处理,特征生成,模型生成和对模型的部署与使用。
微软最近发布了一系列的认知服务,这些服务已从牛津项目(Project Oxford)进化成了Azure预览服务。这些认知服务已在语音、文本分析、面孔识别、情绪识别和其他类似能力方面进行了预训练。除了你自己训练的模型之外,这些认知服务也可以作为补充。
中级玩家平台Databricks
Databricks是一个基于Apache Spark的商业云服务。而Apache Spark是一个开源集群计算框架,它包括一个机器学习库、一个集群管理器、一个类似Jupyter的互动式笔记本、仪表盘和工作项目列表。Databricks公司由Spark的发明者建立,因此通过Databricks服务你可以毫不费力地玩转那些Spark集群。
它的库MLlib包含范围广泛的机器学习和统计算法,这些算法都针对基于内存的分布式Spark架构方面进行了调整。MLlib中包含总结性统计、相关、取样、假设检验、分类和回归、协同过滤、聚类分析、降维、特征提取和转换函数、优化算法等等。换句话说,对有经验的数据科学家来说,它是一个相当完整的工具包。

上面这个具有Python代码的Databricks笔记本页面展示了一种对公共自行车租用数据集的分析方法。在笔记本的这个部分,我们正在训练管道,通过使用交叉验证来运行多个梯度上升树回归。
Databricks被设计为可规模化的、相对易用的数据科学平台,其目标使用者是那些已了解统计学并能做一点编程的人。要有效地使用它,你需要知道一些SQL,也需要从Scala、R或Python中了解其中之一。如果你精通你所选择的语言,那就更好了,因为这样你就可以集中精力学习Spark了。你可以通过在免费的Databricks社区版集群上运行Databricks笔记本的样本来尝试进行最初的使用。
高手请进:谷歌机器学习云
谷歌最近宣布了多个机器学习相关的产品。其中最有趣的是云学习和云语音API,这二者目前都限于预览。谷歌的翻译API和云视觉API已经可供使用,其中谷歌翻译可以识别语言并在80多种语言和方言之间进行翻译,而云视觉可以从图像中识别多种特征。从谷歌发布的试用版看,它们表现得不错。
谷歌预测(Google Prediction )API能够训练、评估和预测回归和分类问题,但用户无法选择采用什么算法。(它起源于2013年。)
我在TensorFlow的Github存放目录中检查了它的代码。我读了它的一些C、C++和Python代码。我也研读了TensorFlow网站和白皮书。TensorFlow让你能够从电脑桌面、服务器或手机上对单个或多个CPU或GPU部署计算。它拥有内置的各种训练算法和神经网络算法。从挑战难度的极客角度看,如果难度总分10分那么它能得9分。它的难度不仅超出了商业分析师的能力,也会令许多数据科学家感到困难。
谷歌翻译API、云视觉API和新的谷歌云语音API都是预训练的机器学习模型。根据谷歌的说法,它的云语音API使用神经网络技术与支撑Google app语音搜索和支撑Google Keyboard语音打字的技术是同一种。
Haven OnDemand,还差那么一点点
Haven OnDemand目前拥有音频-视频分析、连接器、格式转换、图形分析、惠普实验室沙盒、图像分析、政策、预测、查询概览与操作、搜索、文本分析和非结构化文本索引等API。我用一个随机集做试验,探索了这些API是如何被调用和使用的。
Haven语音识别只支持6种语言和方言。它对我的高质量美式英语测试文件的识别准确率还行,但并不完美。
Haven OnDemand连接器(connector)让你能够从外部系统中提取信息并通过Haven OnDemand API来更新信息。该连接器已相当成熟,这是因为它是基于惠普的搜索服务IDOL的连接器。文本提取API使用惠普企业的KeyView服务来从你提供的文件中提取元数据和文本内容;由于KeyView已相当成熟,该API能处理超过500种不同的文件格式。
图形分析是一组预览服务,它只按照一个从英文维基百科训练而来的索引而工作。你不能用你自己的数据来训练它。
我使用图像分析API试验了条形码识别,结果还不错。我也试验了面孔识别,这时它对我的测试图像的识别没有它对惠普企业自己的样本识别得好。图像识别目前还只限于一组固定的企业标识,用处有限。

Haven OnDemand的条形码识别API可以从图像文件中圈出条形码(见红色方框)并把它转化为数字,即便条形码的表面是弯曲的、是20度倾斜的或模糊的。该API不会进一步去查询条形码数字和识别产品。
我失望地发现,惠普企业的预测性分析只处理二元分类问题:没有多类别分类,也没有回归,更不要提无引导学习了。这严重限制了它的应用范围。不过从好的一面看,它的训练预测API能对CSV或JSON数据进行自动验证、探索、分离和准备,并用于训练决策树、Logistic回归、朴素贝叶斯,并支持多参数的向量机(SVM)二元分类模型。之后,它会用数据中的评估部分来测试分类器,并将最优的模型发布为服务。
Haven OnDemand搜索使用IDOL引擎来执行对公共和私有文本索引的高级搜索。文本分析API则既能进行简单的自动补全、词汇扩展,也能进行语言识别、概念提取和情感分析。
IBM Watson预测分析服务
IBM提供了基于Watson的机器学习服务和IBM SPSS Modeler。IBM实际上为开发者、数据科学家和商业用户这3类用户准备了不同的机器学习服务。
SPSS Modeler是一个Windows应用,最近也可以在云上使用它了。Modeler的个人版包括数据导入和导出、数据自动准备、整理和抽取转换装载(ETL)等功能。它拥有30多种基本的机器学习算法和自动建模方法,具有R语言可扩展性,可使用Python脚本。更昂贵的版本则能通过IBM SPSS分析服务器来使用大数据,使用 Hadoop/Spark、冠军-挑战者功能、A/B 测试,文本与实体分析以及社交网络分析。
SPSS Modeler中的机器学习算法、特征选择方法和对支持格式的选择,都可以拿来和Azure机器学习、Databricks Spark机器学习的相应部分进行比较。甚至它的自动建模(训练并评估多个模型并挑选最优者)部分也可以拿来比较,尽管在SPSS Modeler中,用户更容易弄明白如何自动建模。
IBM的Bluemix云容纳了预测性分析网络(Predictive Analytics Web)服务,该服务可以应用SPSS模型,向你提供评价性API,而你可以在你的apps里调用它。除了网络服务外,预测性分析也支持批量工作,以对额外数据进行重新训练和重新评估。
Watson名下除了预测性分析之外,还有18种Bluemix服务。其中Alchemy API向用户提供三种服务(Alchemy 语言、Alchemy 视觉和 Alchemy 数据),它能够让商业公司和研发者建立认知性应用,从而理解文本和图像中的内容和语境。
概念扩展API可以分析文本并基于语境学习类似的词语或词组。概念洞察API可以把你提供的文件与既有的基于维基百科话题的概念图连接起来。而对话服务则让你能够使用自然语言和用户概要信息,通过对话界面设计应用与用户互动的方式。文档转换服务把单一的HTML、PDF或微软Word文档转换为标准化HTML,纯文本或可以用于其他Watson服务的JSON格式的答案单元集。

我使用Watson分析一个常见的出租自行车数据集,得到了一个具有48%预测力的决策树。该表格并未区分工作日骑车者和非工作日骑车者。
语言翻译服务则处理多个知识领域和语言对。在新闻和谈话领域,语言对包括英语、巴西式葡语,法语、现代标准阿拉伯语和西班牙语。在专利领域,语言对包括英语、巴西式葡语、汉语、韩语和西班牙语。翻译服务可以从62种语言中识别出某个纯文本的语言。
自然语言分类器服务运用认知计算技术,通过在你的类别和短语集上进行训练,可以返回对句子、问题或短语的最佳匹配类别。个性洞察力服务从交易和社交媒体数据(其中每个个体至少要提供1000个单词的数据)中判断个体的心理特质,这些特质被记录在JSON格式的性格树之中。关系提取服务则把句子分析为多个部分,并通过语境分析来探测这些(词性和功能)部分之间的关系。
其他Bluemix服务有的能提高搜索结果的相关性,有的在6种语言的文本和语音之间进行转换,有的从文本中识别情绪,还有的能分析视觉场景和对象。
Watson分析服务使用了IBM自己的自然语言处理工具,让商业分析师和其他非数据科学家能更容易地用机器学习。
哪家平台最适合你?
你应该基于你自己和你的团队的技能来衡量上面这些企业提供的机器学习服务。
对数据科学家和那些拥有数据科学家的团队来说,选择面很宽。擅长编程的数据科学家还可以做更多的事:Google、Azure、Databricks比Amazon、SPSS Modeler需要更多的编程技能,不过前3个也因此变得更具灵活性。
在Bluemix上运行的Watson服务在云应用方面为开发者提供了额外的预训练能力。若干Azure服务、3个谷歌云API和若干Haven OnDemand API也在文档内容方面提供了预训练能力。
谷歌TensorFlow库适用于那些能流利使用Python,C++或C的高端机器学习编程者。谷歌的云机器学习平台似乎适用于了解Python和云数据管道的高端数据科学家。
尽管亚马逊机器学习和Watson分析服务宣称它们的目标用户是商业分析师或“任何商业职位”,我很怀疑他们这一说法能否实现。如果你需要开发机器学习应用,但却缺乏统计数学或编程背景,我认为你应该在你的团队中引入懂这些的人。
各家机器学习云大比拼
---亚马逊机器学习
优点:
- 它替你选择模型,从而简化了模型选择过程
- 它根据模型提供实时和批量预测
- 当你需要时,它可以为模型提供恰当的图表和诊断
- 能够处理来自S3, RDS MySQL和Redshift的训练数据
- 能自动进行一些文本处理
- 可以用Linux,Windows或Mac OS X使用API
缺点:
- 不包括探索性数据分析
- 不允许分析师调整改变算法
- 无法导入或导出模型
---微软Azure机器学习
优点:
- 有多种模型可供选择,还能用R或Python编写新模型
- 使用拖拽界面,可以轻易地进行模型设计和训练
- 可以使用Azure云中的真实数据进行探索性数据分析
- 入门免费
- 从任何网络浏览器都可进入它
缺点:
- 要拥有数据科学家的技能才能选出恰当特征、找到最佳模型
- 探索性数据分析需要一定的Python或R编程能力
- 将 R 结果传递给流程时会发生困难
---Databricks及Spark 1.6
优点:
- 对Spark cluster进行摆弄和规模化变得很简单
- 为数据科学家提供了范围广泛的机器学习工具
- 提供了一个使用R, Python, Scala, SQL的协作性笔记本界面
- 免费入门,价格低廉
- 容易对产品工作进度进行安排
缺点:
- 不如BI产品好用,虽然整合了一些BI产品
- 用户需要熟悉编程、数据分析和机器学习算法
---惠普企业Haven OnDemand
优点:
- 强大的文档格式转换能力
- 强大的企业搜索能力
- 价格合理
缺点:
- 有些服务尚不成熟
- 有些服务范围狭窄,限制了其适用范围
---IBM Watson 与预测分析服务
优点:
- 点几下鼠标,就能使用SPSS Modeler提供的范围广泛的模型
- Bluemix预测分析网络服务表现良好,价格合理
- Watson Bluemix服务为开发者提供了优质、价格合理的技术能力
- Watson分析服务使用自然语言,从而让那些经验较少者也能轻易地建立模型
缺点:
- 按照当前标准,SPSS MOdeler价格昂贵
- Bluemix预测分析网络服务要求SPSS模型Watson分析服务在易用性方面用力过猛
来源:新智元









