企业如何处理灾难恢复问题?存储与灾备
无论企业对于突发事件的准备有多么全面,也不可能会有一套灾难恢复计划是能够完美的应付各种不测的。正如分析机构Gartner所指出的那样:“想要完全避免所有一切的灾难风险的威胁是不可能的。”
但是,如果企业有一套明确的行动计划的话,那么某些停机中断事故其实是可以避免的,或者至少可以说,可以尽量减轻其所带来的影响。在Computer Weekly网站最新一次的CW500俱乐部活动上,与会的IT领导人们共同交流了关于他们及其同行在处理和应对灾害事件时的真实经历。
“我们为客户提供了食物餐点的链接,但如果人们不能下订单的话,对我们来说无疑是一大灾难。”在线外卖服务供应商Just Eat公司的技术经理Amarpal Attwal表示说。
“我所经历的第一次灾难事件是:由于丹麦的一处数据中心的服务器出现超载,导致我们所有网站的出现瘫痪。”他说。这个问题是源于容量规划所造成的。Attwal承认,该公司在其数据中心业务运营方面,还没有足够的灵活敏捷性。
对于Just Eat公司而言,另一种形式的灾难是:企业工作人员无法连接到内部工具。他所经历的第二次灾难事件是发生在该公司英国总部的一次电力故障,此次故障的影响更大。“英国总部是所有其他国家办事处的枢纽。”他补充说。彼时,该公司没有准备应对灾害的计划。
Attwal说,该公司不得不仔细排查其基础设施,并在企业业务层面创建了一套关于如何针对灾难场景及其成本影响进行应对的框架概述。他说:“我们需要从一个灾难恢复的视角来了解什么对我们来说是最为重要的,最终,我们建立起了一套涉及企业整个系统的架构。”
其所带来的结果是,虽然该公司仍然在丹麦运营其数据中心,但Just Eat公司现在实施了cloud native。Atwall说:“我们已经把一切工作负载均迁移到了亚马逊网络服务(AWS),不仅仅是我们的电子商务平台,同时也包括我们的企业基础设施。”
正是由于在亚马逊网络服务上部署了公司的网站和业务系统,Just Eat现在已经从企业的办公室中移除了物理服务器。其结果是各个的办事处都连接到同一个核心。“我们也是SaaS (软件即服务)的忠实粉丝——我们要保护我们的数据,并尽量减少故障运行失败。”Attwal补充道。
Just Eat采用了一个预期失败的政策,并以该方式架构其云系统。IT团队使用了一款开源的工具称为Chaos Monkey,该工具最初是由Netflix开发的,目的旨在能够在AWS系统组件中故意造成故障以测试反应,并学习如何防止他们扰乱整个操作。
在处理数据中心灾难的最佳实践方面,Attwal说:“实践就是一切。我们在我们的备灾方案中引入了这一概念,例如,所有人都无法登录的话。我们该怎么办?于是,我们选择了处理场景模拟的理论,然后付诸实际的运行。”这样的模拟情况应定期运行,而不是一年一次。
考虑人的因素
Attwal说,企业往往忽视了灾难恢复(DR)规划:“我们对于发生某些相关场景的应对规划还没有引起高度重视,例如,如果有20名员工同时离开公司,应如何处理。”为了解决这些模拟场景,Just Eat公司举办了一些圆桌讨论会,以便让员工们广泛的探讨和分享他们的专业知识。
为了避免所有的专业知识诀窍只被一个人了解,Just Eat组成了一个专门的项目团队。Attwal说:“我们更注重目标,并组织了一个专门的团队,这可以帮助降低风险。”
在投资管理公司Brewin Dolphin的业务连续性的负责人柯克·兰利也认为,人的元素在灾害管理中往往被忽视了。
“跨部门的协作是一项相当艰巨的任务。我曾经在许多企业工作过,负责业务连续性的人员与企业的IT人员往往在相互间形成了孤岛。”他说。
兰利认为,业务连续性专家需要了解关于IT的合理人数配额:“在任何类型的企业,你都会发现有人会掐你的团队。如果你在关键团队失去了一名理财规划师;或者在金融服务团队失去了一名投资经理,这固然是一个商业问题,但这同时也是一个IT问题,因为你必须使用IT向所有的客户分配一个新的投资经理。”
就算总部发生灾难,灵活的工作团队也可以使企业的业务继续保持正常运行进行。但正如Just Eat的Attwal所指出的那样:“没有什么比面对面的互动是更好的沟通交流模式了。”不要让同一间办公室的人也会妨碍规划,特别是在灾难中的早期阶段,关键负责人员需要一步一步的协调各个流程,这需要调用该公司的灾难恢复策略。
随着企业越来越多地使用专用的数据中心和云服务,因此,在正确的时间和正确的职位上安置关键人员就显得是至关重要的。戴尔软件系统顾问的高级经理阿德里安·莫尔说:“让20个人在一个数据中心,围着大约四台机架并尝试一起做一切工作是很难的。你企业的灾难恢复中心实际上是一处办公室,那里才应该是您企业专业天才人员和辅助硬件所在。”
莫尔认为,数据中心灾难恢复计划往往没有顾及关键IT人员的因素:“很多人都忘了为业务部门提供服务,并确保业务部门积极和富有成效的工作的IT部门的同事。”
他说,虽然企业经常会主动的进行弹性数据中心运行,但IT部门往往忘了究竟是谁需要访问数据中心:“想想看,有多少被访问设备和应用程序需要执行灾难恢复计划。”
精心策划
当系统开启并运行时,没有人会表示担心,人们只会在系统出现故障时才注意到。然后,企业的业务部门就会不断的询问:“我们如何才能尽快恢复并再次运行?”这是一个关键性的问题,全国建设协会灾难恢复部门负责人詹姆斯·洛奇说。
他说:“在任何特定的某些时刻,许多企业都很难确定一款关键系统将需要多长时间来恢复。”他说。当系统出现故障时,其再次启动和运行的时间并不能总是可以准确估计的。
一家典型的银行将需要运行三种类型的系统,洛奇说。保持与客户互动的系统;业务系统等进行销售处理;数据中心及其系统。显然,有些系统在不同的时间内对业务会有更大的可视性。
“如果当所有其他的系统均正常运行时,销售系统发生故障,那么,较之发生一次更广泛的数据中心故障,其会具备较高的优先级。”洛奇说。业务连续性专家需要考虑的另一个因素是,关键系统将随着时间的不同而改变。例如,电子邮件系统中白天的工作时间往往比在夜间下班时间更重要。
在他所使用的这个灾难恢复模型中(见下图表),洛奇为任何给定的业务系统恢复正常运作规定了时限,指定其如果发生故障需要多长时间恢复。
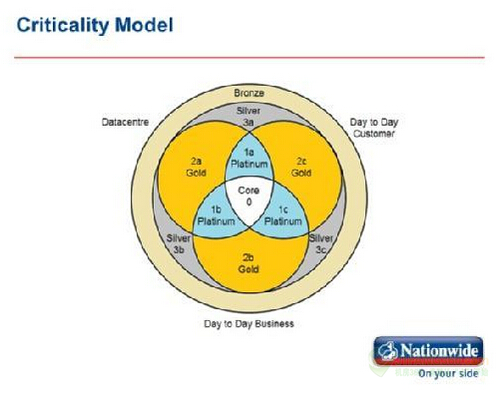
从灾难恢复的角度来看,数据中心的核心组件,如网络或Active Directory软件是一样重要的,因为它们会影响业务正常运行的能力。不幸的是,其往往是难以准确估计整个数据中心需要多长时间才能重新联机。
传统上,当一处数据中心发生中断后,让一切业务重新恢复正常运营估计大约需要24到48小时。洛奇说,但通过将数据中心分割成各个组成成分,有可能对于企业的恢复时间做出更准确的评估。“这是对数据中心建立更精细的恢复的一种方法。”他说。
自上而下的策略
根据Gartner的分析师介绍,企业灾难恢复策略问题的产生是因为灾难恢复规划并不是从企业整体战略角度出发,并排序适当的优先事项和目标自上而下建立的。举例来说,Just Eat公司就只是建立了一个框架,用于处理未来的事件。
这种策略需要明确规定:关键责任人必须在何处待岗——特别是如果数据中心系统需要重新启动时。显然,这些人员需要访问业务连续性站点并必须在重启系统时具备系统的访问权限。这涉及到业务连续性管理者对于所需专业IT人员的充分理解。
虽然系统仪表板将就相关问题提醒IT团队,但企业内部的其他部门可能也需要被迅速提醒,尤其是在当前客户一旦在网站或移动App遇到问题是,他们会第一时间将问题发布到社交媒体。“通常情况下,客户可能会意识到发生了一次中断事故,并会在八分钟内开始将这些消息发表到社交媒体。”洛奇说。
因此他建议企业要主动和积极的管理Twitter等社会媒体。根据企业类型的不同,社交媒体监测和团队管理媒体是必不可少的手段,洛奇说。
没有人能充分保护主要系统不会发生任何故障。但是,正如洛奇所指出的那样:“由此所带来的企业声誉的损害可能会远远大于企业的实际经济损失。”因此,现代企业灾难恢复策略需要包括的不仅仅是让IT系统迅速重新联机。









